Download PDF
CE Quiz
Abstract
Background
Emergency room (ER) visits in the United States have increased by 15% over the last decade, prompting hospitals to implement fast-track systems to mitigate overcrowding and expedite patient registration. Information is limited regarding the creation of duplicate record data entry errors in a fast-track ER environment and the impact of organizational factors such as work shift and the number of daily admissions.
Methods
This correlational, quantitative study analyzed 19 months of admission data from a healthcare system in Alabama to examine associations between organizational factors—such as work shift and ER admission volume—and the incidence of duplicate record data entry errors.
Results
Results from the data analyses showed statistically significant associations between organizational factors and the number of duplicate record data entry errors.
Conclusions
Health information management (HIM) professionals and ER leaders can benefit from knowledge about the impact of organizational factors on duplicate record data entry errors in the fast-track ER environment, so they can modify policies and procedures to improve data quality and patient safety.
Introduction
Emergency rooms (ER) are fast-paced environments that require workers to adapt to various dynamics. Fast-track admissions are one such dynamic, allowing patients to bypass the patient registration desk, proceed to triage, and be placed in an exam room to see a provider.1 Patient registration is completed prior to the patient’s visit with the provider by a patient registration clerk using a mobile workstation.1,2 Fast-track processes were created to mitigate overcrowding and expedite the ER encounter, particularly for patients with non-life-threatening symptoms.1 ER visits increased by 15% between 2009 and 2019, from 120 million to 138 million visits,3 and a 2015 article estimated that fast-track admissions were implemented in about 80% of ERs in the United States.4 During patient registration in the ER, duplicate records can occur from the patient registration clerk collecting inaccurate demographics, leading to data entry errors such as misspelled first and last names or addresses, incorrect dates of birth (DOB), and transposed Social Security Numbers (SSNs). Duplicate records compromise data quality within healthcare information systems, increasing the risk to patient safety and decreasing the quality of care.5,6 Additionally, duplicate records negatively impact the financial health of healthcare organizations.5 Duplicate records are an ongoing issue in healthcare organizations and have a higher impact in the ER, with 62% of duplicate records being created within the department.7
There is limited research on administrative errors in the emergency room, particularly the impact of duplicate record data entry errors during ER fast-track admissions. Additionally, little attention has been given to the influence of organizational factors such as work shift or daily ER admissions volume and their role in the creation of duplicate record data entry errors. Understanding the impact of these variables is crucial for evaluating and refining workflow processes to improve accuracy and efficiency during ER fast-track admissions. Therefore, the objective of this study was to examine the associations between those organizational factors and the number of duplicate record data entry errors at two acute care hospitals in an Alabama healthcare system.
Methods
This study received approval from the Institutional Review Board (IRB) at Walden University (11-09-21-0693638), ensuring that it adhered to the university’s ethical standards for research involving human subjects. The IRB review process confirmed that the study met all necessary criteria for confidentiality, data security, and ethical research practices.
Study Design
A quantitative, correlational design was used to examine the associations between organizational factors (work shift and the number of ER admissions) and the number of duplicate record data entry errors (first and last name misspellings, incorrect DOB, and transposed SSNs).
The target population included two hospitals, with 125 and 323 beds, respectively, that admitted all patients through fast-track. Notably, this timeframe encompassed the onset of the COVID-19 pandemic, which may have influenced patient admission patterns, staffing, and workflow, potentially affecting the generalizability of the findings.
Data Sources and Collection
The data used in this study were provided by the participating healthcare system in the form of aggregated, de-identified patient records, initially collected under the healthcare system’s oversight. As this is a secondary analysis, the dataset was not generated specifically for this research. A Data Use Agreement (DUA) was established, indicating that the researcher (S. Harris) was not involved in the original data collection and ensuring compliance with privacy and security regulations. This arrangement allowed for the use of previously collected data while maintaining patient confidentiality and adhering to all applicable ethical guidelines.
Data collection was completed through a custom medical record report consisting of duplicate data entry errors from the fast-track admissions at the Alabama health system. The health information management (HIM) staff completed a manual verification process of the duplicate data entry errors on the report. This involved comparing patient demographics to determine whether the duplicates were true duplicates. Additionally, the HIM director deidentified all protected health information (PHI) on the report to maintain compliance with the Health Insurance Portability and Accountability Act (HIPAA). Duplicate record pairs were renamed as Record 1 and Record 2. Data entry errors from the duplicate record pairs were manually counted to determine the number of errors created during the study timeframe across four staggered shifts within 24 hours: 5:00 am-11:00 am (Shift 1), 11:00 am-5:00 pm (Shift 2), 5:00 pm-11:00 pm (Shift 3), and 11:00 pm-5:00 am (Shift 4).
Statistical Analysis
Statistical tests conducted for the data analysis included the Kruskal-Wallis H Test, Chi-Square Test of Independence, and Linear Regression. The following research questions and hypotheses guided the study:
Research Questions and Hypotheses
To examine factors influencing duplicate record data entry errors in a fast-track ER setting, this study posed the following research questions and hypotheses.
Research question (RQ) 1: Is there an association between work shift and frequency of duplicate record data entry errors, after controlling for the number of daily ER admissions?
-
Null hypothesis (H01): There is no significant association between work shift and the frequency of duplicate record data entry errors after controlling for daily ER admissions.
-
Alternative hypothesis (Ha1): There is a significant association between work shift and the frequency of duplicate record data entry errors after controlling for daily ER admissions.
RQ2: Is there an association between the number of daily ER admissions and the frequency of duplicate record data entry errors?
-
H02: There is no significant association between daily ER admissions and the frequency of duplicate record data entry errors.
-
Ha2: There is a significant association between daily ER admissions and the frequency of duplicate record data entry errors.
RQ3: Is there an association among work shift, the number of daily ER admissions, and the frequency of duplicate record data entry errors?
-
H03: There is no significant association among work shift, daily ER admissions, and the frequency of duplicate record data entry errors.
-
Ha3: There is a significant association among work shift, daily ER admissions, and the frequency of duplicate record data entry errors.
Results
There was a total of 548 ER admissions at the two hospitals between the study timeframe of March 2019 and September 2020. The sample size determined that 356 duplicate pairs were needed for data analysis. After data cleaning, there were 356 confirmed errors that spanned across 217 days.
Error Analysis
Table 1 summarizes the types of data entry errors differentiated by facility. Across both facilities, name errors were the most frequently occurring type of error, with Hospital 2 reporting the highest number in this category. There were no errors recorded for DOB or address fields, as the health system actively corrects these types of data entry errors through internal messaging protocols.
Table 1.Error Types by Facility
| |
Hospital 1 |
Hospital 2 |
Total |
| Error type |
n |
% |
n |
% |
n |
% |
| Name |
69 |
92.0% |
268 |
95.4% |
337 |
94.7% |
| Social security number |
6 |
8.0% |
13 |
4.6% |
19 |
5.3% |
| Date of birth |
0 |
0% |
0 |
0% |
0 |
0% |
| Address |
0 |
0% |
0 |
0% |
0 |
0% |
| Total |
75 |
100.0% |
281 |
100.0% |
356 |
100.0% |
Additionally, the HIM director provided the total number of ER admissions in a separate report. However, the admissions data could not be separated by shift. Instead, work shifts were determined based on the time of admission recorded for each patient record. This limitation highlights a constraint in analyzing error patterns across shifts but still allowed for an assessment of errors within the defined timeframes.
RQ1 Analysis
To answer RQ1, the Chi-Square Test of Independence and the Kruskal-Wallis H Test statistical tests were used. The Chi-Square Test of Independence was employed to determine whether duplicate record data entry errors were independent of the work shift. During the study period, data was collected for 217 days, with each day including four shifts:
-
Shift 1: 5:00 am to 11:00 am
-
Shift 2: 11:00 am to 5:00 pm
-
Shift 3: 5:00 pm to 11:00 pm
-
Shift 4: 11:00 pm to 5:00 am
There were 217 opportunities for either errors or no errors to occur on a total of 868 shifts. The errors were categorized as either “no errors recorded” or “errors recorded.” A similar distribution of errors across shifts would suggest an association between duplicate record data entry errors and work shift, while an uneven distribution would suggest no such association. The analysis revealed a strong, statistically-significant association between the number of duplicate record data entry errors recorded and the work shift: χ2(3) = 254.697, p < 0.001, Cramer’s V = 0.542. Specifically, the test indicated that errors were recorded as follows:
-
148 of 217 shifts (68.2%) occurring during Shift 1
-
35 of 217 shifts (16.1%) occurring during Shift 2
-
Four of 217 shifts (1.8%) occurring during Shift 3
-
71 of 217 shifts (32.7%) occurring during Shift 4
These results indicated that duplicate record data entry errors occurred differently across the four working shifts; however, errors were more consistent during Shift 1 compared with Shifts 2, 3, and 4.
Kruskal-Wallis H Test Analysis
The Kruskal-Wallis H test was conducted to determine whether the differences in recorded error counts varied significantly across the four defined work shifts.
The test results revealed a statistically significant difference in the number of errors between the shifts, χ2(3) = 262.856, p < 0.001. This indicated that error rates were not uniform across all shifts and that one or more shifts had a higher frequency of data entry errors.
Pairwise Comparisons
Pairwise comparisons were conducted using Dunn’s (1964) procedure with a Bonferroni correction for multiple comparisons (Table 3). The analysis revealed a statistically-significant difference in the number of recorded errors between the shifts. The mean ranks were as follows:
-
Shift 1 mean rank = 608.75
-
Shift 3 mean rank = 443.70
-
Shift 2 mean rank = 372.21
-
Shift 4 mean rank = 313.34
All comparisons had p-values < 0.05 (Table 3). Shift 1 (5:00 am to 11:00 am) had significantly more errors than Shifts 2, 3, and 4.
Table 2.Chi-Square Results: Recorded Duplicate Records Data Entry Errors and Shift
| Shift |
Errors, n (%) |
No errors, n (%) |
| Shift 1: 5:00 am to 11:00 am |
148 (68.2) |
69 (31.8) |
| Shift 2: 11:00 am to 5:00 pm |
35 (16.1) |
182 (83.9) |
| Shift 3: 5:00 pm to 11:00 pm |
4 (1.8) |
213 (98.2) |
| Shift 4: 11:00 pm to 5:00 am |
71 (32.7) |
146 (67.3) |
Note. χ2 = 254.697; df = 3; p value < 0.001; Cramer’s V = 0.542.
Table 3.Pairwise Comparisons of Shift Results
| Sample 1 |
Sample 2 |
Test statistic |
Standard error |
Standard test statistic |
p value |
Adjusted
p value |
| Shift 3: 5:00 pm to 11:00 pm |
Shift 2: 11:00 am to 5:00 pm |
58.873 |
19.310 |
3.049 |
0.002 |
0.014 |
| Shift 3: 5:00 pm to 11:00 pm |
Shift 4: 11:00 pm to 5:00 am |
(-)130.357 |
19.310 |
(-)6.751 |
0.000 |
0.000 |
| Shift 3: 5:00 pm to 11:00 pm |
Shift 1: 5:00 am to 11:00 am |
295.406 |
19.310 |
15.298 |
0.000 |
0.000 |
| Shift 2: 11:00 am to 5:00 pm |
Shift 4: 11:00 pm to 5:00 am |
(-)71.484 |
19.310 |
(-)3.702 |
0.000 |
0.001 |
| Shift 2: 11:00 am to 5:00 pm |
Shift 1: 5:00 am to 11:00 am |
236.532 |
19.310 |
12.249 |
0.000 |
0.000 |
| Shift 4: 11:00 pm to 5:00 am |
Shift 1 : 5:00 am to 11:00 am |
165.048 |
19.310 |
8.547 |
0.000 |
0.000 |
RQ2 Analysis
Simple linear regression was used to answer RQ2, examining the association between the number of daily ER admissions and the number of duplicate record data entry errors for fast-track ER admissions. The prediction equation was:
Number of errors = 1.062 + 0.014 x daily admissions
The number of fast-track admissions statistically predicted the number of duplicate record data entry errors, AF(1, 215) = 7.140, p = 0.008. There was a predicted increase in errors of 0.014 (95% CI:0.004 - 0.024) for every additional person admitted. The R2 value revealed that 3.2% of the variance in the number of errors could be explained by the number of admissions.
Although the association between the number of duplicate record data entry errors and the number of daily fast-track ER admissions was not strong, the results indicated that admissions could predict the number of errors. This means that as daily admissions increased, there was a slight but measurable rise in the number of errors. However, the low R² value suggests that other factors beyond the number of admissions played a much larger role in contributing to errors. Figure 1 illustrates that while a few days showed spikes in both admissions and errors, these increases did not consistently indicate a strong relationship.

Figure 1.Line Frequency of Admissions and Errors
Figure 1. Line Frequency of Admissions and Errors
RQ3 Analysis
A series of simple linear regression tests were conducted to examine the associations between work shift, the number of daily ER admissions, and the number of duplicate record data entry errors for fast-track ER admissions. Although ER admissions could not be determined per shift due to reported aggregate totals, scatterplots of duplicate record data entry errors per work shift were plotted to understand the impact of admissions on data entry errors.
Figure 2 indicated a linear relationship between the variables for Shift 1, as the residuals were normally distributed on the P-P plot. Additionally, the linear regression results revealed F(1,215) = 13.022, indicating a significant association between duplicate record data errors and the number of daily ER admissions, with p < 0.0001 (Table 4). This suggests that for Shift 1, higher daily ER admissions were associated with an increase in the number of data entry errors. Shift 1 appeared to be particularly sensitive to fluctuations in admission volume.

Figure 2. Simple Linear Regression Scatterplot: Shift 1 (5:00 am to 11:00 a.m.)
Figure 2.Simple Linear Regression Scatterplot: Shift 1 (5:00 am to 11:00 a.m.)
Table 4.Multiple Linear Regression: Coefficients
| Shift |
Unstd. coefficients |
Std. coefficients |
t |
p value |
Result |
R2 |
| B |
Std. error |
Beta |
| Shift 1: 5:00 am to 11:00 am |
|
|
|
|
|
|
|
| (Constant) |
0.211 |
0.233 |
|
0.906 |
0.366 |
F(1, 215) = 13.022,
p < 0.001 |
0.06 |
| Admissions |
0.020 |
0.005 |
0.239 |
3.609 |
< 0.001* |
| Shift 2: 11:00 am to 5:00 pm |
|
|
|
|
|
|
|
| (Constant) |
0.192 |
0.127 |
|
1.510 |
0.133 |
F(1, 215) = 0.0002,
p = 0.989 |
9.345E-07 |
| Admissions |
4.218E05 |
0.003 |
0.001 |
0.014 |
0.989 |
| Shift 3: 5:00 pm to 11:00 pm |
|
|
|
|
|
|
|
| (Constant) |
0.011 |
0.045 |
|
0.241 |
0.809 |
F(1, 215) = 0.076,
p = 0.783 |
3.543E-04 |
| Admissions |
0.000 |
0.001 |
0.019 |
0.276 |
0.783 |
Shift 4: 11:00 pm to 5:00 am
(Constant) |
0.648 |
0.158 |
|
4.108 |
0.648 |
F(1, 215) = 2.643,
p = 0.105 |
0.01 |
Figures 3–5 show that results indicated no linear relationship between the number of daily ER admissions and the number of duplicate record data entry errors for Shifts 2, 3, and 4. This lack of a relationship suggests that admissions volume alone may not have significantly impacted error rates during these shifts.

Figure 3. Simple Linear Regression Scatterplot: Shift 2 (11:00 a.m. to 5:00 p.m.)
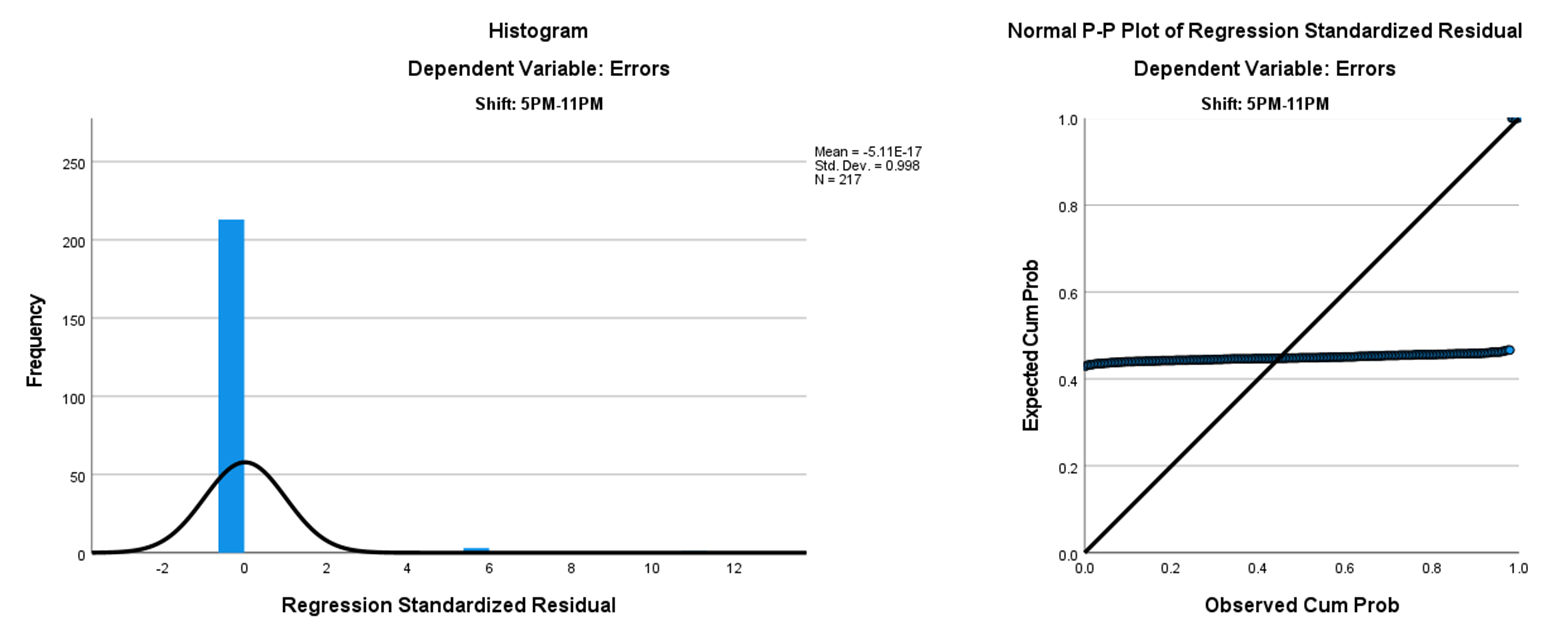
Figure 4. Simple Linear Regression Scatterplot: Shift 3 (5:00 pm to 11:00 pm)
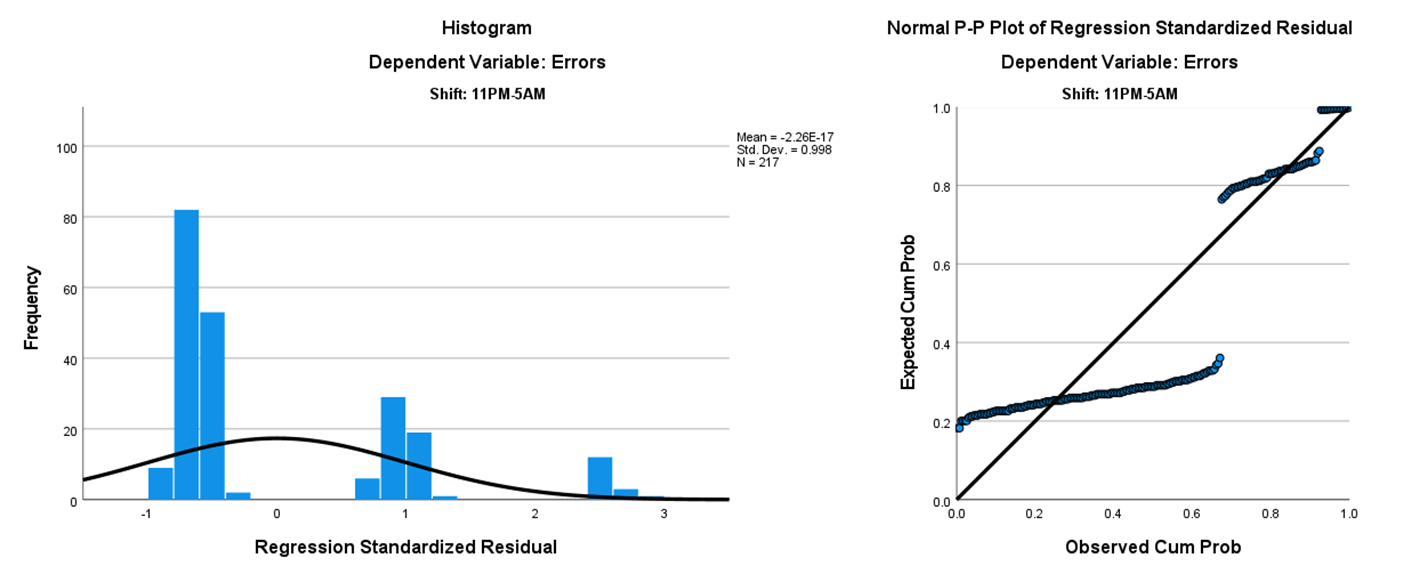
Figure 5. Simple Linear Regression Scatterplot: Shift 4 (11:00 pm to 5:00 am)
Figure 5.Simple Linear Regression Scatterplot: Shift 4 (11:00 pm to 5:00 am)
Predictive Analysis of Daily Admissions
The number of daily admissions was not a significant predictor of the number of duplicate record data entry errors during Shifts 2, 3, and 4. However, during Shift 1, the number of daily admissions accounted for 5.7% of the variation in the number of errors, indicating a statistically significant association between the number of daily admissions and duplicate record data errors. We assumed that the statistical significance of errors for Shift 1 was due to the higher number of admissions during that time. However, without admissions data per shift, this assumption could not be confirmed.
Discussion
RQ1: Work Shift and Duplicate Record Data Entry Errors
The first research question examined whether work shift was associated with the number of duplicate record data entry errors for fast-track ER admissions.
The initial finding that more errors occurred during Shift 1 (5:00 am–11:00 am) contrasted with previous literature, which suggested that medical errors are more likely during evening or overnight hours (7:00 pm–7:00 am) and the evening shift (7:00 pm–3:00 pm).8,9 This discrepancy prompts several considerations. First, the absence of reported errors during Shifts 2-4 raises the possibility of underreporting rather than a true lack of errors. Without detailed admission time data for each individual error, it is difficult to determine whether errors truly did not occur during these shifts or were simply not captured. The inability to separate admissions by shift thus limited our ability to draw firm conclusions about the influence of work shift on error rates. This lack of temporal precision, combined with the fast-track admissions process, may have introduced inconsistencies or biases into the recorded error patterns.
These limitations highlight the need for more comprehensive and precise data collection methods, including exact admission timestamps. Such enhancements would allow researchers to verify whether the observed distribution of errors is accurate or a result of data limitations. In addition, the absence of detailed admission time data means it was not possible to assess whether higher admission volumes or workflow issues occurred specifically during Shift 1. Without this data, it is challenging to determine if these factors may have contributed to the higher error rates. Future studies could also consider how variations in staffing levels, workload, or environmental factors may influence both the occurrence and reporting of errors across different shifts. Understanding these patterns can help inform targeted strategies aimed at improving data quality during specific shifts.
Conditions unique to the early morning hours (Shift 1, 5:00 am–11:00 am) may be contributing to increased data entry challenges. Operational or staffing challenges during this time could amplify the impact of admission volume on error rates. Targeted interventions, such as adjusting staffing levels or workflow processes during Shift 1, could help reduce error rates and improve overall data quality. Further analysis with more granular data is needed to validate this relationship and identify additional contributing factors. Improving data granularity and comparability with existing literature, such as by incorporating more precise timestamps and stratifying by shift, would allow for more definitive conclusions regarding the relationship between work shift and duplicate record data entry errors.
Considering these findings, the need to explore additional variables such as staffing levels, shift timing, or workload distribution is clear. These factors may influence both the occurrence and reporting of errors, highlighting the importance of more precise data collection methods. Moreover, other factors, such as workflow processes or staff experience, may play a larger role in determining error frequency. Future research should explore these variables more comprehensively.
RQ2: Daily ER Admissions and Duplicate Record Data Entry Errors
The second research question addressed the associations between the number of daily ER admissions and the number of duplicate record data entry errors for fast-track ER admissions. There was a significant association between the number of daily ER admissions and duplicate record data entry errors. Although the percentage was small, this study is the first to demonstrate that daily ER fast-track admissions can predict duplicate record data entry errors.
Previous literature noted that increased admissions can cause healthcare workers to rush through tasks, leading to medical errors in up to 1 in 20 admissions.10,11 The specific time of day was not considered in this study as the admission times were not available in the admissions report; therefore, specific admissions times indicating an influx could not be determined for the study.
The results suggest that higher admission volumes or workflow issues may contribute to error rates, particularly during Shift 1. Variations in staffing levels, workload, or other operational conditions may influence the occurrence and reporting of errors. Therefore, future research should explore how these variables, such as shift timing and workload distribution, contribute to error patterns in relation to daily ER admissions.
RQ3: Combined Impact of Work Shift and ER Admissions on Errors
The third research question examined the combined impact of work shift and number of daily ER admissions on duplicate record data entry errors. Statistically significant associations were found between the number of errors and admissions, specifically for Shift 1. The number of daily ER admissions accounted for 5.7% of the variation in the number of duplicate record data entry errors. Although data to determine admissions per shift were not available, it is possible that Shift 1 experienced an increased number of ER admissions, contributing to the higher number of errors.
The results suggest that work shift-related factors, such as staffing levels and workload, may have influenced the observed variations in error rates, particularly during Shift 1. Further research is needed to better understand the relationship between admissions, staffing levels, and error rates across different shifts.
Limitations
The study has several limitations. Because the researcher (S. Harris) did not control the original data collection process, there may be potential limitations related to data accuracy, completeness, or the consistency of variables recorded. Additionally, the study relied on information gathered for purposes other than the research objective, which may have limited the types of analyses performed or the depth of interpretation possible.
First, the data entry errors examined only included names and social security numbers (SSNs) because the HIM department worked with patient registrars and other hospital staff to proactively correct other types of data entry errors. Consequently, names and SSNs were the only data entry errors analyzed in the study. Additionally, the data collected from the duplicate report were limited to specific types of data displayed.
Furthermore, the study was limited by the unavailability of daily ER admissions data stratified by shift, which prevented the analysis of admissions on a per-shift basis. As a result, it was not possible to assess how shift-related factors specifically influenced the occurrence of duplicate record data entry errors. Additionally, the study was conducted during the onset of the COVID-19 pandemic, which may have introduced atypical admission patterns, staffing challenges, and workflow disruptions, potentially affecting the results and their generalizability.
Finally, the generalizability of the study findings may be limited to hospitals and health systems with ER fast-track admissions that employ a proactive approach to mitigating data entry errors.
Future Studies
These findings should be viewed as preliminary, providing a foundation for further inquiry rather than definitive conclusions. Given the constraints of the current data, future research could treat these results as a pilot study from which new questions emerge. For instance, incorporating the time of day for each patient admission may offer clearer insights into when errors occur, and exploring additional sites such as multiple hospitals, larger health systems, or teaching institutions could yield more generalizable findings. Larger health systems can present a duplicate record error rate of up to 20%.12 Previous studies on duplicate record data entry errors have included a teaching hospital and up to 71 hospitals across several countries.5,13
Further investigation may compare duplicate record data entry errors in health systems that employ a fast-track process based on nonurgent symptoms against those, like the health system in this study, that fast-track all patients regardless of symptoms.1 Additionally, ensuring that facilities have robust reporting capabilities and minimal data limitations will enable researchers to examine a broader range of variables, ultimately producing more comprehensive and actionable results.
Conclusions
This study’s findings offer valuable insights into the organizational factors influencing duplicate record data entry errors during ER fast-track admissions. By identifying the association between work shifts, admission volume, and the frequency of errors, this research provides actionable evidence that ER leaders and HIM professionals can use to refine workflows, update policies, and implement target interventions. Such data-driven adjustments can enhance data integrity, reduce administrative burdens, and ultimately improve the quality of patient care. Strengthening the accuracy of patient records ensures that clinical decisions are based on reliable information, thereby fostering better patient outcomes, bolstering patient satisfaction, and supporting the overall efficiency of the healthcare system.
Disclosures
The authors have nothing to disclose.
Funding
The authors received no funding for this research.
Author Contributions
S. Harris designed and implemented the research and analyzed the results. S. Harris and S. Houser wrote the manuscript.
Submitted: February 04, 2025 EDT.
Accepted: March 23, 2025 EDT.
© American Health Information Management Association
Bibliography
-
1.
Gasperini B et al. Is the fast-track process efficient and safe for older adults admitted to the emergency department?
BMC Geriatrics. 2020;30(1):1-6. doi:
10.1186/s12877-020-01536-5. PMID:32345234
-
2.
Alishahi Tabriz A et al. Association between adopting emergency department crowding interventions and emergency departments’ core performance measures.
Am J Emerg Med. Published online 2020. doi:
10.1016/j.ajem.2019.04.048
-
3.
Quattrini V, Swan B. Evaluating triage practices in emergency department fast tracks.
Int J Nurs Health Care Res. Published online 2022:173. doi:
10.29011/IJNHR-173.1000673
-
4.
Hwang CE et al. Effect of an emergency department fast track on Press-Ganey patient satisfaction scores.
West J Emerg Med. 2015;16(1):34-38. doi:
10.5811/westjem.2014.11.21768
-
5.
Banton CL, Filer DL. The impact of multiple master patient index records on the business performance of healthcare organizations. J Technol Res. 2014;5:1-11.
-
6.
Cohen R et al. Transfusion safety: The nature and outcomes of errors in patient registration.
Transfus Med Rev. 2019;33(2):78-83. doi:
10.1016/j.tmrv.2018.11.004
-
7.
Landsbach G. Study analyzes causes and consequences of patient overlay errors. J AHIMA. 2016;87(9):40-43.
-
8.
Cappadona R et al. Individual circadian preference, shift work, and risk of medication errors: A cross-sectional web survey among Italian midwives.
Int J Environ Res Public Health. 2020;17(16):5810. doi:
10.3390/ijerph17165810
-
9.
Manias E et al. Medication error trends and effects of person-related, environment-related, and communication-related factors on medication errors in a pediatric hospital.
J Pediatr Child Health. 2020;55(3):320-326. doi:
10.1111/jpc.14193. PMID:30168236
-
10.
Brennan PA et al. Review: Avoid, trap, and mitigate—An overview of threat and error management.
Br J Oral Maxillofac Surg. 2020;58(2):146-150. doi:
10.1016/j.bjoms.2020.01.009
-
-
12.
Harris S, Houser S. Double trouble: Using health informatics to tackle duplicate medical record issues. J AHIMA. 2018;89(8):20-23.
-
13.
Waldenburger A et al. Detecting duplicates at hospital admission: Comparison of deterministic and probabilistic record linkage.
Stud Health Technol Inform. 2016;226:135-138. doi:
10.3233/978-1-61499-664-4-135